
PlacementVal

AI is coming for your jobs. Actually wait, it is not. Well, maybe it will. This is how the labor market is being screwed up. See what is going to happen to the job market! And on and on and on.
It is hard being a student these days. The vague dissatisfaction that folks felt in college for decades has been replaced with a vague understanding that it is all pointless. But articulating this explicitly risks upsetting the apple-cart, and starting an avalanche in the bargain.
Because asserting that college is pointless is one thing. Trying to figure out what should replace it and how is a jungle cat that no one wants to bell, so why bother? And so we carry on, knowing that what we do is clearly the wrong answer to a question that nobody wants to ask.
That question being this one:
What exactly do we get when we spend a lot of time and money in acquiring a degree in an AI-first world?
But we’re getting ahead of ourselves. Let’s go back to the start of this thought process, and question our very first assertion. How do we test the proposition that college is pointless?
Is There A Point to Acquiring a Degree?
Going to a college gives you a degree, first and foremost. In an Indian context, said degree is valuable because it gives you a job. You also get a peer network, you get (some) learning, but the basic reason you go to a college and suffer through it is because you need the nice shiny certificate that says you got the degree. That piece of paper is the key that unlocks the myriad treasures of the labor market, and that’s why you go to college.
If you don’t believe me, I invite you to go spend time in a college with students in their last year, and in that last academic year, make sure you go during their placement semester. You pick the college, I only ask that you go spend time with the students then. I have done this, for many years, and please allow me to assure you that students go to college to get a degree so that they can get a job.
Assuming you accept this proposition to be true, it then makes sense to try and test the next obvious proposition in our chain of thought. That proposition being this one:
For a given college, for this year, are the final year students producing work that is as good (and as cheap) as that which the AI produces?
If the answer to this question is an unambiguous “yes!”, then students stand a good chance of finding employment. If the answer to this question is an unambiguous “no”, then students stand no chance of finding employment. And if the answer lies somewhere in between, we have a fight on our hands.
What we would like to do, then, is run an experiment where we have work that is:
produced by AI
produced by human students (with no input from AI),
produced by AI and students working together.
If the analysis of this dataset yields a result in which we are able to conclusively prove that 1 is winning, good luck to the students concerned. If we can prove that 2 is winning, congratulations to the students concerned. And if we can prove that 3 is winning, we need to think long and hard about how and what we’re teaching students in that college.
What Does Work Mean, Though, Really?
But what does work mean in this context? If I join a firm as an analyst, what exactly does work mean? Because whatever the word work means in that context, it almost certainly means something else in the context of, say, a student who joins an equity research firm. A student who joins a software firm to do coding will be doing different work from both of these.
Economists have spent time and effort in answering this question, and one way to think about it is that work really consists of different tasks1. Some tasks may be common across many jobs, while others may be of a more specialized nature. For example, taking notes while attending a meeting, and then circulating those notes to all attendees is a task. And back in 2006, when I was a junior employee, tasks such as this one were routinely assigned to junior folks. But today, your LLM of choice will transcribe the meeting, generate high level notes, assign follow-ups, and share that file with all attendees automatically.
You may still need the junior employee around, because there are other tasks that still (hopefully) remain in their scope of work. But this specific task has now been automated.
This little thought experiment allows us to refine our original question a little bit.
It’s All About Tasks
That question now becomes:
What we would like to do, then, is run an experiment where we have the modal tasks - the core work that actually justifies your salary - in different lines of work that is:
produced by AI
produced by human students (with no input from AI),
produced by AI and students working together.
What are modal tasks? Well, as a business analyst in my first job, sure I took meeting notes. Sure I wrote emails, scheduled meetings, booked conference rooms for calls and all that. But the task that made my bank account go ka-ching at the start of every month was that of building out logistic regression models.
If the company that hired me back then was able to instead get an LLM to build out equally good logistic regression models at maybe one-tenth the price, then it makes sense for the firm in question to hire the LLM instead.
So what if we took a particular college, and dug through the placement history of that college for the last five years? What if we found the typical profiles that recruiting firms hired students for from that college? What if we spoke to the recruiting firms, and got an idea of the modal tasks for each of those profiles?
Setting up the experiment
I spoke to my current best non-human friend, a guy called Opus, and it helped me come up with ten not-so-hypothetical tasks for such a college:
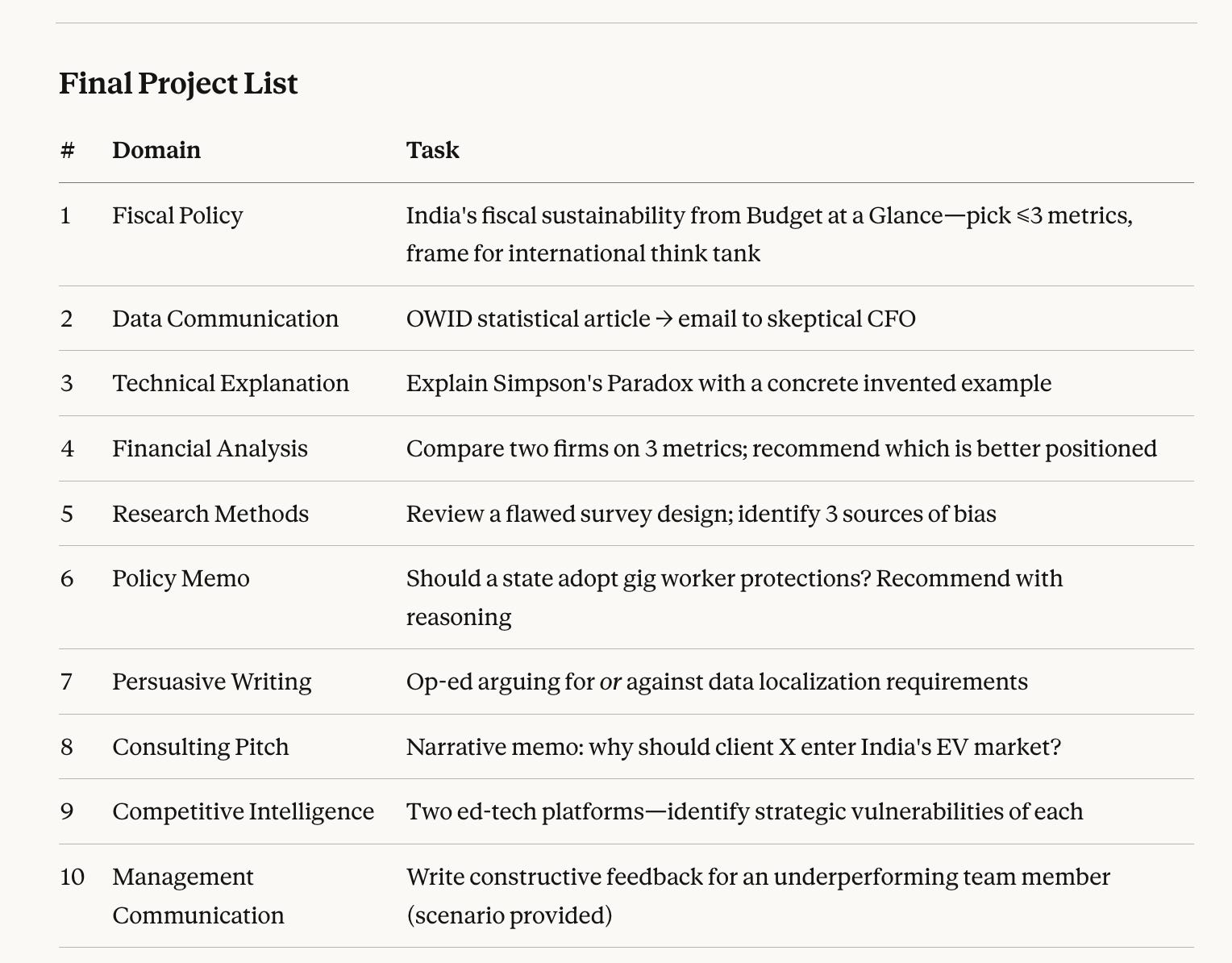
What do we do with these ten tasks? In brief: design tasks, recruit students, split into three arms, anonymize outputs, have alumni review blind, analyze statistically. What you're about to read about is called an eval—a structured way to measure how well a system performs on tasks that matter.
Here’s what I would do, in detail:
Speak to ten alumni from the college who are presently employed in firms that work in areas where tasks such as this one might be done regularly. So maybe a think tank for the first domain, maybe a telecommunications firm for the second, etc.
Ask these ten alumni to carefully design a specific task based on these inputs. So for example, I would ask an alum who is currently in an HR role in a large organization to work on creating a task that was as close as possible to the ten task on this list. This might include a brief about the employee in question, mock records of their performance in this review cycle, other details that might be necessary (role, org structure, pay scale, vintage at the company, etc.)
Also ask that alum to carefully design an “ideal” output. That is to say, what would an ideal end product look like for the task that they themselves have designed.
Once I have ten such neatly detailed tasks, along with an idea of what an ideal version of the end product would look like, I would then go out and recruit nine volunteers from final year students, per each of the ten tasks. So ninety volunteers in total (9 volunteers per task x ten such tasks).
For each task, divide these nine volunteers into three teams of three each.
One team would be the Human Only team. This team would try and do the task in question entirely by themselves. They can use computers and the internet, but they cannot use AI at all.
Another team would be the AI+Human team. This team gives this task to an LLM, along with a prompt to do the task. They can design the prompt themselves, or take help from other folks (including the LLMs themselves!). Once they get the output of the AI, they can edit it to make it better, but this part of the work they have to do themselves, no other human being is allowed to help. The edits can be done iteratively with the help of an AI, or by themselves, that is entirely up to them.
The third team would be the AI Only team. This team gets the task done with the help of an LLM of their choice, the only condition being that it must be one of the paid versions of the latest and greatest model from the three major labs.2
Once this is done, take each of the nine submissions (3 versions of Human Only, 3 versions of AI+Human, and 3 versions of AI only), and anonymize them. I would remove all identifiable traces (name of writer if it is a word doc, any identifying headers and footers, and personal identifiers etc). Simply looking at the document should give you no idea about who has written it - that is the objective.
Name each variant of the first task as T1A, T1B, T1C…T1I. The ordering would be completely random, and only I would have the master key. That is, I know which one is which (so T1A might be Human Only Version 2, while T1B might be AI Only Version 3), but no one else does. I would put all of these anonymized and randomized versions in a folder.
Do this for all ten projects.
Give each such project folder to three separate reviewers. Each reviewer would be asked to rate each project along, say, three different dimensions. A score of 1 would mean the submission is unusable, while 5 would mean it is perfect. For example, one dimension might be Thoroughness, another might be Imaginativeness, and a third might be Readiness Score. Why three, and why these three? Great question, and both answers can change depending on your needs and preferences. Chat with your friendly neighborhood LLM about this, and feel free to improve upon my suggestion. In fact, I insist that you do so!
I would also ask each reviewer to stack rank all nine versions. That is, they have to assign a rank to each version, based on which one they liked the most (rank 1), all the way through to which one they liked the least (rank 9). If you do the math, you’re looking at thirty reviewers (3 per project, ten such projects).
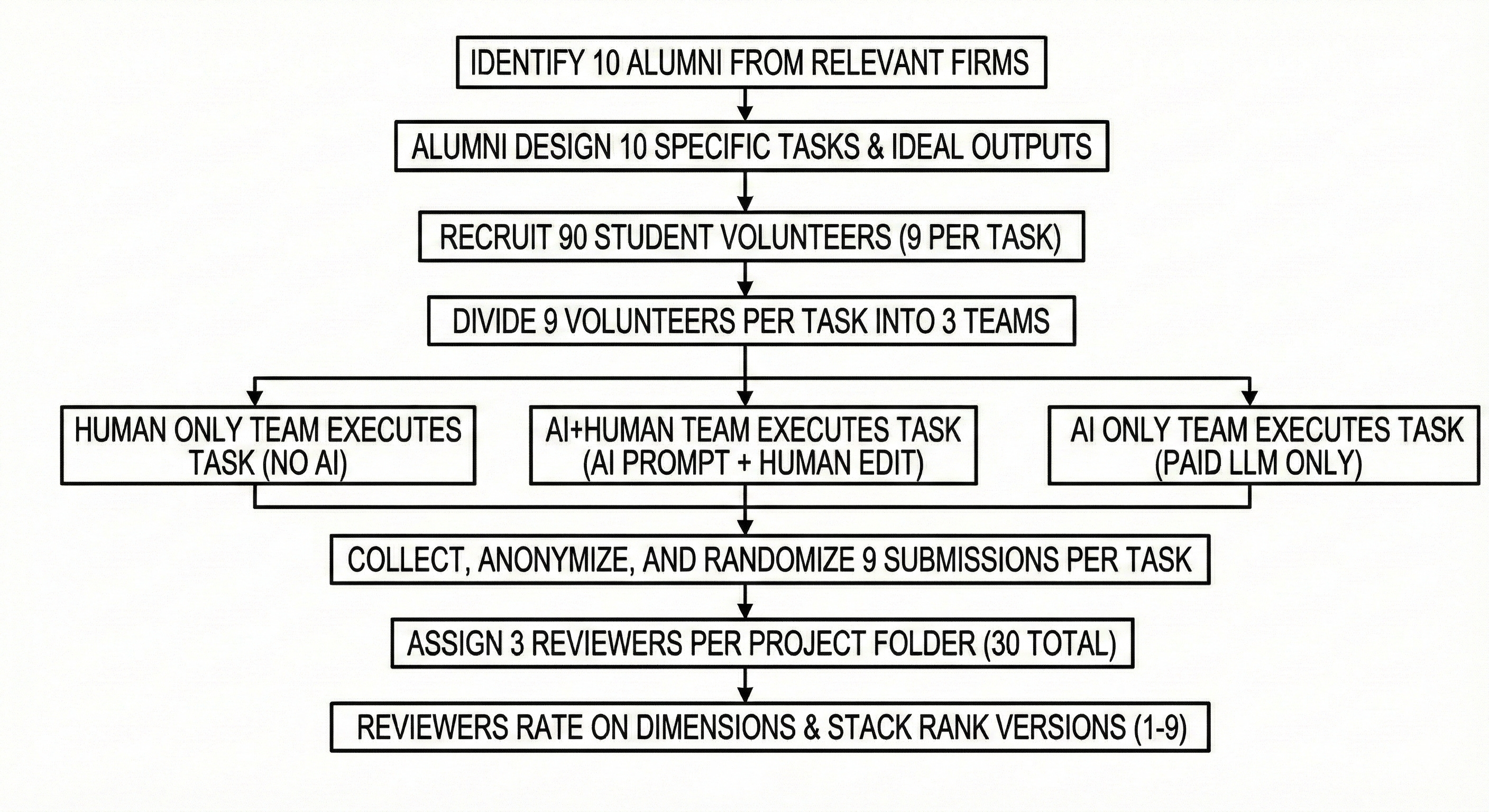
The Analysis
So now you’ll have a spreadsheet that looks something like this:
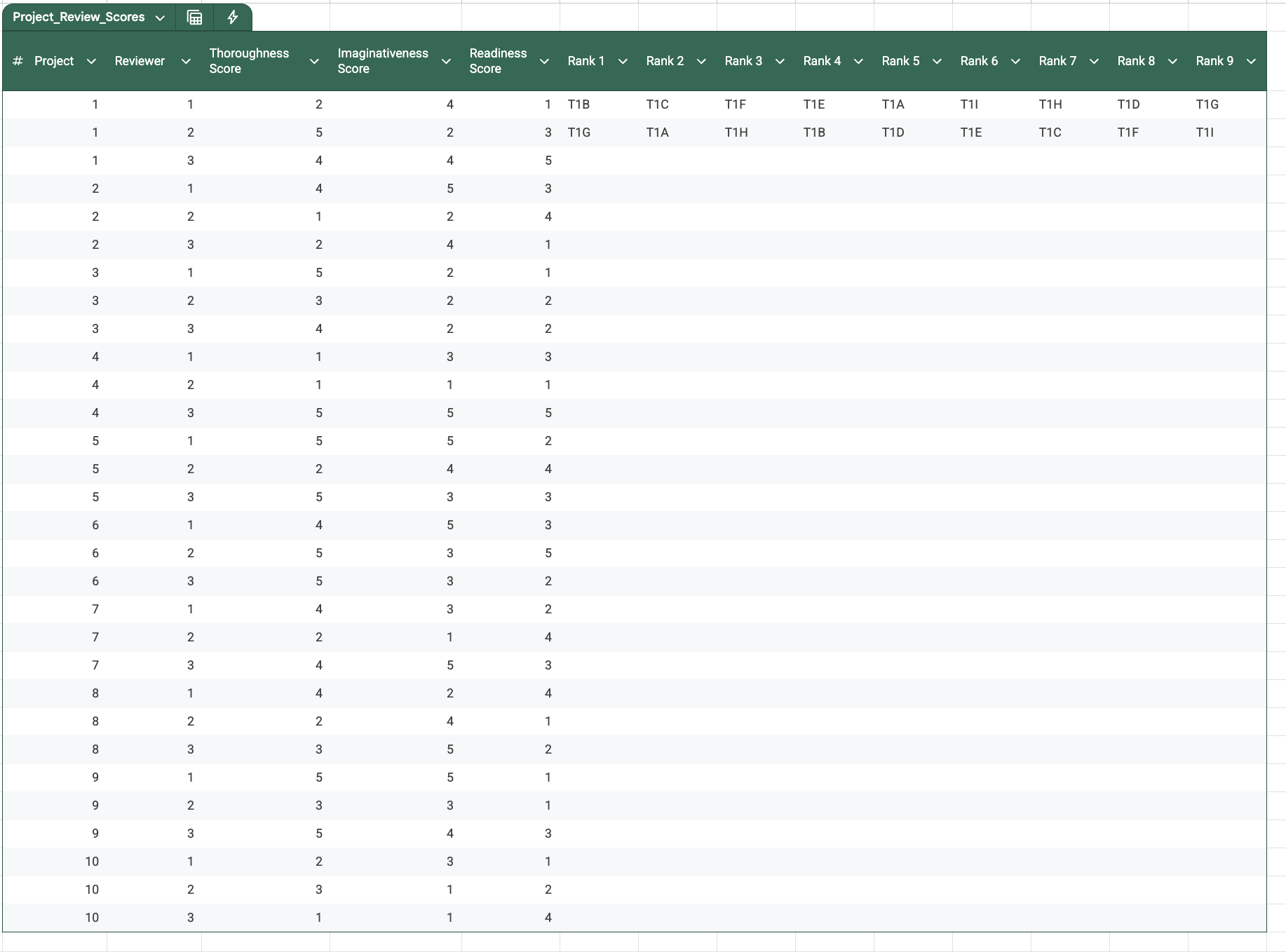
So all right, now you have the data to analyze. What sort of tests can you run on data such as this?
LLMs and your statistics textbooks will both tell you that you can run a test called Friedman’s test to analyze the ranks. You could do a lot of post-hoc analyses, you could compute mean ranks - there’s a lot to be done here, and you should have fun chatting with humans and LLMs about awesome and fun ways to run an analysis of this data.
The questions that need to be answered are these:
Is there a statistically significant pattern to the ranks? That is, is the assignment of ranks random, or does a pattern emerge? Which arm of the experiment (Human+AI, AI Only, Human Only) tends to do better, and is it a close run thing, or not particularly?
Ditto for ratings
To what extent do the reviewers agree with each other for the rankings?
Ditto for ratings
The first two questions tell you who won. The latter two tell you whether the judges were measuring the same thing
TMKK?
What do you do once you have these results?
For one thing, you have clear, statistically valid answers about which kind of work is best for each project. This tells you something about how good your students, are, how good the models are, and the extent to which students are able to improve upon the output of the models. For example, you may end up finding out that when it comes to the students in your college and working without AI, they are not so great at persuasive writing, but they’re excellent at financial analysis. But with AI, they’re awesome at fiscal policy analysis. And so on and so forth.
Publicize the hell out of your work. Write a blogpost about it. Create a YouTube video. Record a podcast. Write up a white paper. Hell, write up a full academic paper. Go present your work at conferences. Help other colleges set up these experiments.
Repeat the experiment when the latest and greatest models are replaced by the latest-er and greatest-er models (we’re about three months away as of mid-Jan 2026, at worst).
Go tell recruiting firms that you know how to run evals, and you can run evals for them (congratulations, if you have actually done all of this work, because now you really do know how to design and run an eval)
The Bottomline
AI is here. It will affect the labor market, and entry level jobs are going to be hard to come by. But rather than wait for other folks to do the research and write up the papers, make use of the abilities that have been unlocked for you by AI, and show the world that you can get ahead of the game.
And above all, realize that this applies to you regardless of whether you are actually in college or not. Pick workflows that make up the modal tasks in your current job, and run these tests on them. Because it is just a matter of time before somebody else does it anyway.
And if you’ve made it this far, you may enjoy reading the GDPval paper. But if you are a student today, you should read it regardless of whether you enjoy it or not.
You learn best by doing, and in 2026, there is no excuse for not doing. Get started!
There is a rich literature here, see this paper for starters
These are not hard and fast rules. You should carefully figure out variants of these rules that make the most sense to you. Maybe the prompts for the AI+Human team and the AI Only team need to be exactly the same for each task? Maybe these prompts should be signed off by a professor? Decide what works best for the exact aspect that you are trying to test in these experiments - this is the fun part of setting up an experiment like this, so have at it!
In many ways, degrees serve as the ultimate filtering mechanism for employers. The hierarchy of IIT > NIT > State Govt Colleges > Private colleges provides a broad heuristic/prior that keeps the conventional recruitment process from collapsing under the sheer volume of applications. Until the hiring process evolves to evaluate actual output, formal degrees remain structurally necessary.
This 'differentiation' extends far beyond the workplace it is deeply embedded in the social fabric, particularly in the Indian arranged marriage context. It is highly improbable for parents to approve of a non-degree holder for their children. Changing this deeply ingrained societal behavior will likely take much longer than the technological shift itself
That was a very interesting read man!!