
Exponentials Are Hard For Us To Understand

Back in March 2020, I’d written a post with the title “Understanding exponential functions in the times of the corona virus”:
Exponential functions essentially imply that y is going to change pretty darn quickly, even for very small changes in x.
And what that means is that if you have, say, time on the horizontal axis (x), then whatever you’re measuring on the y-axis will change pretty darn quickly for even relatively small passages of time.
In class, you’re taught the same thing, but in fancypants symbols and diagrams, and the typical reaction is like so:

Except, as it turned out, covid helped us all get used to the idea of working with exponentials.
Not So Fast!
Maybe not, says Julian Schrittwieser:
The current discourse around AI progress and a supposed “bubble” reminds me a lot of the early weeks of the Covid-19 pandemic. Long after the timing and scale of the coming global pandemic was obvious from extrapolating the exponential trends, politicians, journalists and most public commentators kept treating it as a remote possibility or a localized phenomenon.
Something similarly bizarre is happening with AI capabilities and further progress. People notice that while AI can now write programs, design websites, etc, it still often makes mistakes or goes in a wrong direction, and then they somehow jump to the conclusion that AI will never be able to do these tasks at human levels, or will only have a minor impact. When just a few years ago, having AI do these things was complete science fiction! Or they see two consecutive model releases and don’t notice much difference in their conversations, and they conclude that AI is plateauing and scaling is over.
As always, the entire post is worth reading. One graph in particular, that I’ve shared earlier on these pages too, is particularly compelling:

The important thing to note with this graph is the way data is represented on the y-axis. Each unit movement upwards represents 10 times the current value. So four seconds becomes forty seconds (with one move up), and forty seconds becomes 400 seconds (that’s just two moves upwards on the y-axis.)
So if the same rate of improvement holds, by this time next year we’ll have models that can think and execute on tasks that will take up to ten hours. By this time the year after that, it’ll be up to a hundred hours.
I would at this point have said that you “get the picture”, but that’s the point of today’s post. I worry that we do not, in fact, get the picture.
But It Can’t Do X
Yet.
The missing word in this section header is “yet”. Julian points us to GDPval:
GDPval: a new evaluation designed to help us track how well our models and others perform on economically valuable, real-world tasks. We call this evaluation GDPval because we started with the concept of Gross Domestic Product (GDP) as a key economic indicator and drew tasks from the key occupations in the industries that contribute most to GDP.
What’s the basic idea?
GDPval covers tasks across 9 industries and 44 occupations, and future versions will continue to expand coverage. The initial 9 industries were chosen based on those contributing over 5% to U.S. GDP, as determined by data from the Federal Reserve Bank of St. Louis. Then, we selected the 5 occupations within each industry that contribute most to total wages and compensation and are predominantly knowledge work occupations, using wage and employment data from the May 2024 US Bureau of Labor Statistics (BLS) occupational employment report(opens in a new window). To determine if the occupations were predominantly knowledge work, we used task data from O*NET(opens in a new window), a database of U.S. occupational information sponsored by the U.S. Department of Labor. We classified whether each task for each occupation in O*NET was knowledge work or physical work/manual labor (requiring actions to be taken in the physical world). An occupation qualified overall as “predominantly knowledge work” if at least 60% of its component tasks were classified as not involving physical work or manual labor. We chose this 60% threshold as a starting point for the first version of GDPval, focusing on occupations where AI could have the highest impact on real-world productivity.
This process yielded 44 occupations for inclusion.
And what comes next?
For each occupation, we worked with experienced professionals to create representative tasks that reflect their day-to-day work. These professionals averaged 14 years of experience, with strong records of advancement. We deliberately recruited a breadth of experts—such as lawyers from different practice areas and firms of different sizes—to maximize representativeness.
Each task went through a multi-step review process to ensure it was representative of real work, feasible for another professional to complete, and clear for evaluation. On average, each task received 5 rounds of expert review, including checks from other task writers, additional occupational reviewers, and model-based validation.
The resulting dataset includes 30 fully reviewed tasks per occupation (full-set) with 5 tasks per occupation in our open-sourced gold set, providing a robust foundation for evaluating model performance on real-world knowledge work.
And now for the graph that you were waiting for:
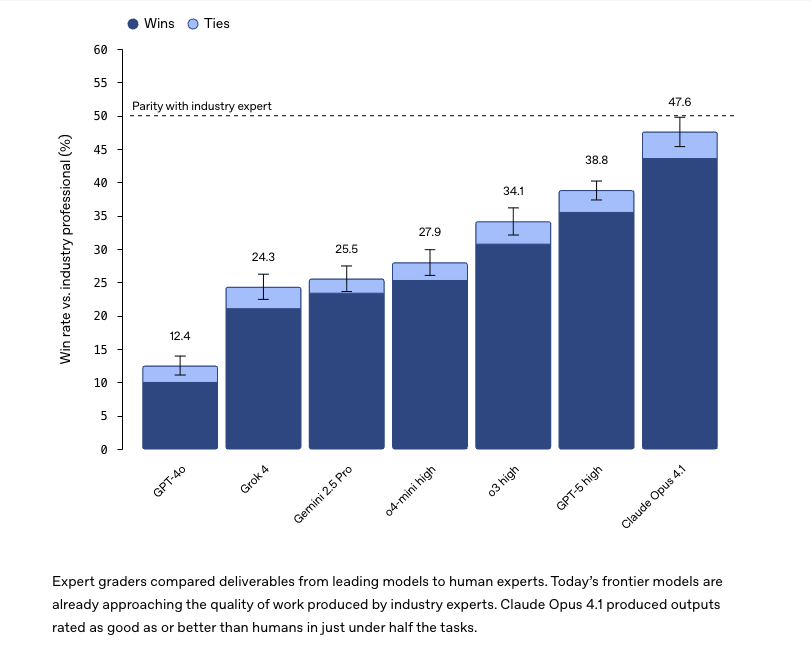
Now remember, you need to keep in mind two things:
The best models are already halfway there, or close enough
Models can think ten times longer with every passing year
And that’s why the word “yet” should really be added to the title of this section.
Pick Your Own Test
I used to make a living teaching people economics and statistics. And when it comes to knowledge within the fields that I am supposed to have expertise in, it is already over. The current version of LLMs from all of the major labs already know more econ and stats than I ever will, and its not even close1.
But I have picked another test to keep track of, and I picked it about two years ago:
How long before I can ask AI to create a movie just for me? Or just me and my wife? Or a cartoon flick involving me and my daughter? How long, in other words, before my family’s demand for entertainment is created by an AI, and the supply comes from that AI being able to tap into our personal photo/video collection and make up a movie involving us as cartoon characters?
Millions of households, cosily ensconced in our homes on Saturday night, watching movies involving us in whatever scenario we like.
Now, back when I wrote that paragraph, we’d just barely gotten over watching Will Smith eat spaghetti. Today, in 2025, we’ve come a long, long way:
How did I do it?
I’m talking of entire movies by 2028, and we can only create eight second long videos so far. Do I still think we’re on track?
Let’s do the math:
Eight second videos as of June 2025
So let’s assume eighty seconds by June 2026
Eight hundred seconds by June 2027
Eight thousand seconds by June 2028
That’s about 133 minutes, and that’s good enough for me. So sure, I think we’re on track. Of course, it’s not just length. There’s consistency, a tight script, and a million other things. But why assume that each of those will also not see 10x improvements each year?
I may well turn out to be wrong and if we were to bet on it, I’d probably lose. But not by much, I don’t think, and I do think we’d be pretty damn close. Hour long videos made on demand by June 2029? I’ll bet INR 10,000 on that.
Here’s The Verge on the topic:
Over the past few months, major players in the gen AI space, including OpenAI, Google, and Meta, have been meeting with film studios in hopes of establishing close working relationships. Lionsgate, for example, signed a deal with Runway to produce an in-house generative AI model trained on the studio’s port of films. In late July, Amazon invested in Showrunner, a company that bills itself as the “Netflix of AI” and specializes in clunky, user-created animation generated with text prompts. And earlier this month, OpenAI announced its plans to produce a feature-length movie called Critterz that is meant to convince studios that they can and should produce projects entirely with gen AI.
There has also been a sharp uptick in partnerships / collaborations between established filmmakers — David Goyer, Darren Aronofsky, and James Cameron immediately come to mind — and outfits who are presenting AI-centric workflows as a solution to some of the industry’s larger ongoing issues with ballooning budgets that studios are struggling to make back against a generally depressed box office.
I worry for these film studios. Convincing studios that “they can and should produce projects entirely with Gen AI” is only a couple of steps removed from being able to convince everybody that they can and should produce projects entirely with gen AI, and I hope (for their sake) that the film studios are solving for the equilibrium.
But the point isn’t about me winning this specific bet. The point is that you too should pick your own “can’t do X right now” and see how long it takes to get to X. And have fun taking part in the debate about where AI is today and where it will be tomorrow, but the real thing you should be doing is keeping a track of how close AI is getting to your personal X3.
TMKK?
Keep these points in mind:
Don’t think about what AI can’t do today, ask what it is likely to do tomorrow, and plan accordingly
AI will be at least twice as good as it is today by next year, and can think at least ten times longer than it does right now
The world will change faster this year than it did last year, and next year will be faster still
AI is a technology. It’ll enable good people to do better things much faster, but it will also help bad people to do worse things much faster
Above all, the 2020’s are about learning how to think exponentially. Get better at it.
No, of course that is not all there is to teaching, and I can still do a much, much better job of teaching a human being. That is also, I am glad to report, not even close. But knowing? That’s done and dusted.
I’m on a Mac, so Cmd-C, then Cmd-V
Speaking of X and building it…
I assume that here you are assuming that scaling loss or the bitter truth continues to work and LLMs as AI don't plateau.
Hi Ashish, I’ve been a fan since my first class with you at SIMC and I’ve been reading your newsletters, well, at least most of them for quite some time now. Thank you for these wonderfully written snippets of your thoughts.
I had a question I’d like your opinion on; what about Ai-resilient jobs? AI is inevitable. We’ll need to adapt, but how is the job market going to be for us humans, factoring in the exponential rise of AI over the next few years? Are we doomed or are there any possible job profiles that we can look into?
A friend of mine once said construction was the answer; I disagreed. I know for a fact that we have buildings that were 3D-printed. So if even a traditional, supposedly ‘AI-proof’ job is in jeopardy, what about the rest of us? I’d love to hear your opinion as I’m looking to see how I can upskill with AI so that I’m not redundant in a few years. :)